Appearance
4 - Design
The system has been designed following a microservices architectural style, where each service models a specific subdomain and exclusively owns its data.
The principal objective of the design phase has been to:
- ensure service autonomy.
- separate services persistence management.
- guarantee scalability and fault isolation.
- preserve local consistency while enabling eventual consistency across distributed services.
- separate responsibilities following domain partitioning.
A key design principle adopted is data ownership per service: no service directly accesses the database of another service.
All inter-service coordination occurs either synchronously or asynchronously. This separation allows the system to tolerate partial failures, avoiding where possible cross-services synchronous operations chaining and maintain loose coupling among components.
4.1 - Structure
The identification of domain entities and service boundaries has been guided by principles inspired by Domain-Driven Design (DDD).
The domain has been decomposed into bounded contexts, each representing a coherent business subdomain with its own model and behavior.
This approach has been adopted to:
- reduce semantic ambiguity
- support independence between different subsystems
Each bounded context corresponds to a logically autonomous service, encapsulating:
- domain entities
- business rules
- persistence layer
This alignment between domain boundaries and service boundaries reduces coupling and minimizes the need for distributed transactions, favoring asynchronous coordination and eventual consistency.
Given that, six bounded contexts are identified: user, event, interaction, chat, ticketing and notification.
Moreover, some other services are used: auth (keycloak), media, payments (stripe).
4.1.1 - Core Entities
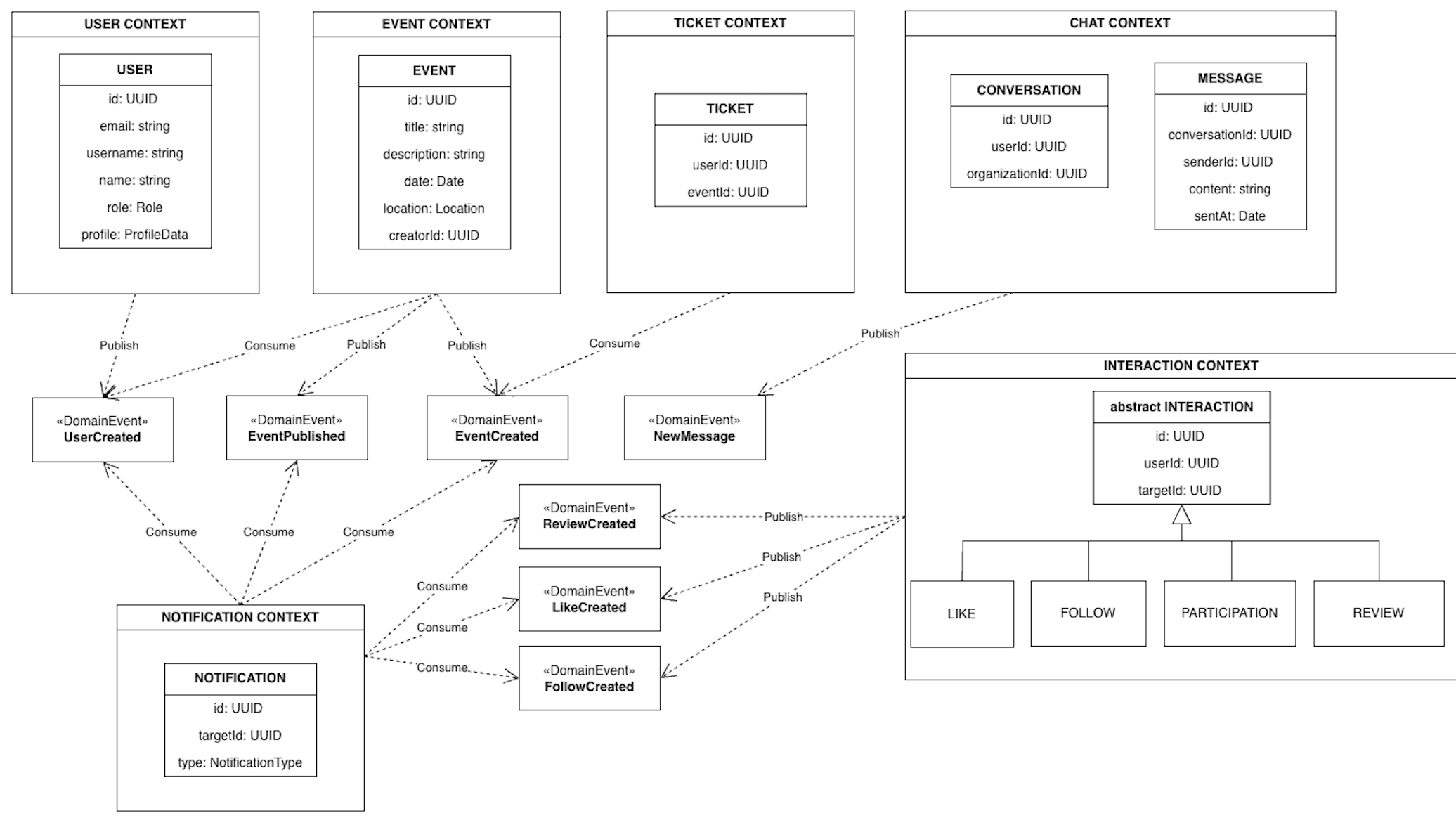
The diagram shows a simplification of the design, not every aspect of the model is represented in details.
The diagram highlights the separation between bounded contexts and the absence of direct structural dependencies across services.
Cross-service relationships are expressed through other entities identifier and domain events rather than object references or shared persistence.
User
Represents a platform account. A User can assume one of two roles:
- Member
- Organization
Attributes include identifier, authentication-related data (account), profile information and events preferences
Event
Represents an activity created by an Organization.
Its attributes include identifier, title, description and all informations about event (e.g. date, time, location).
Ticket
Represents a User's receipt of payment to participate in a Event.
It has its own lifecycle (creation, validation or invalidation) and is modeled independently from Event to avoid coupling financial logic with event management logic.
Interaction
Abstract concept representing user actions.
In particular:
- Like (User → Event)
- Follow (User → User)
- Review (User → Event)
- Participation (User → Event)
Interactions are separated from Event and User entities to enable event-driven propagation of user activities, allowing them to evolve independently from core domain entities.
Conversation
Represents a communication channel between two Users. This entity stores information about the participants involved in the chat and metadata related to the conversation.
Messages are modeled as a separate entity rather than being embedded directly within the Conversation entity. This separation prevents unbounded data growth inside the conversation and allows message data to be managed independently.
Moreover, this design improves efficiency when retrieving the list of conversations. When a user requests the list of active conversations, the system only needs to access conversation metadata without loading all the associated messages. Message data is retrieved only when a specific conversation is opened.
Notification
Represents a system-generated alert that must be sent to specific user.
Examples:
- new follower
- new event published from followed organization
- new message/like/review received
Notifications are derived entities: they originate from domain events generated by other services.
4.1.2 - Domain Events
In addition to static entities, the system models domain events to improve communication between services.
Examples include:
- UserCreated
- EventCreated
- EventPublished
- TicketPurchased
- LikeAdded
- NewMessage
Domain events enable asynchronous integration between bounded contexts and allow the system to maintain eventual consistency.
4.2 - Interaction
Communication between the different components of the system follows two interaction patterns: synchronous request–response and asynchronous event-based communication.
The choice of combining these two approaches allows the system to support direct user interactions while maintaining loose coupling and independent evolution of backend services.
Synchronous interactions between frontend and backend services: Synchronous communication is primarily used for interactions initiated by users through the frontend. In this pattern, a client sends a request to a service and waits for a response before continuing the execution.
This approach is suitable for operations that require an immediate result, such as authentication, event browsing, or ticket purchasing. The response returned by the service confirms the successful execution of the operation or reports possible errors. Using synchronous interactions for user-driven operations simplifies the control flow and ensures that the user receives immediate feedback from the system.
Asynchronous event-driven communication: Communication between backend services is primarily handled through asynchronous event-driven interactions. In this model, when a service completes an operation that may affect other parts of the system, it emits a domain event describing the change that occurred. Other services can subscribe to the events they are interested in and react accordingly. For example, the creation of an interaction or the publication of an event may trigger the generation of notifications or updates in other subsystems.
Consistency and coordination
Each service guarantees consistency within its own boundaries by executing state-changing operations within local transactions. After a transaction completes, the service may emit one or more domain events describing the resulting state change.
Other services process these events asynchronously, updating their own state or triggering additional operations. This approach avoids the need for distributed transactions across services and allows the system to maintain overall coherence through eventual consistency.
4.3 - Behaviour
All of the services in the system follow a common behavioral structure when handling both user requests and inter-service communication. The goal of this design is to maintain strong consistency within each service while enabling coordination between services in a distributed environment.
Three main behavioral patterns can be identified: request-driven operations, event-driven processing and real-time notification propagation.
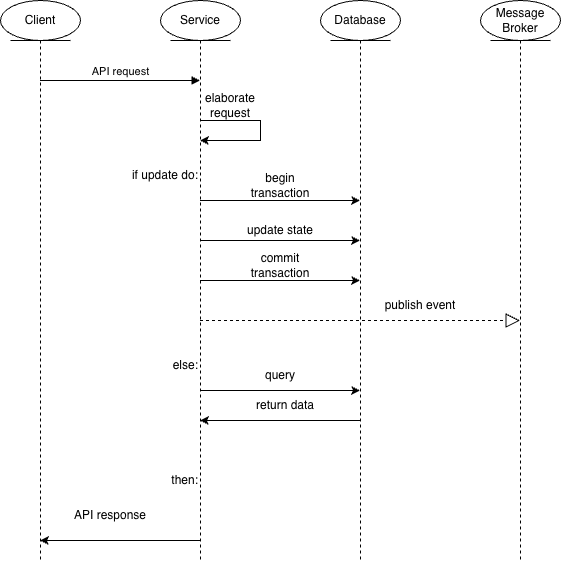
4.3.1 - Request-driven operations
User actions are processed through a request-driven workflow. A request is received by the API interface of the corresponding service and forwarded to the layer responsible for executing the domain logic.
To guarantee consistency, operations that modify the system state are executed within a local transactional boundary.
To guarantee reliability, it's adopted the Outbox Pattern. Instead of publishing events directly after the state update, domain events are first stored in a dedicated outbox structure within the same transaction as the database update. This ensures that the state change and the corresponding domain event recording occur atomically. Once the transaction successfully completes, the events stored in the outbox can be asynchronously delivered to the message broker.
The typical workflow can therefore be summarized as follows:
- A client request is received through the service API.
- The request is validated and processed (optionally, also making synchronous request to other services) by the service logic.
- A local transaction updates the service state and if necessary records in the outbox the domain events describing the change.
- After the transaction completes, the events are asynchronously published.
This pattern guarantees internal consistency within the service while enabling reliable propagation of domain events to the rest of the system.
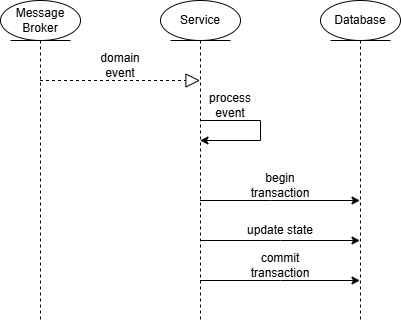
4.3.2 - Event-driven processing
Services also react to domain events generated by other services. When an event is received, the service processes it through its domain logic and may update its internal state or trigger additional events.
This approach enables coordination between bounded contexts without requiring direct dependencies between services.
The typical flow for this interaction is:
- A domain event is received.
- The service processes the event through its domain logic.
- If required, a local transaction updates the service state.
- Additional domain events may be generated.
This event-driven approach allows services to collaborate asynchronously while preserving loose coupling and independent evolution.
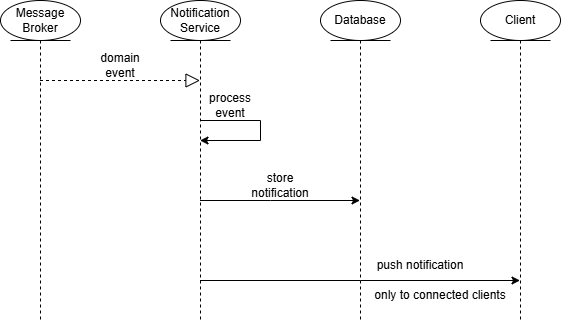
4.3.3 - Real-time notification propagation
A specific behavior is implemented for real-time user notifications. Some domain events represent user actions that must be sent to other users, such as a message or a new interaction. These events trigger the creation of notification entities.
The notification subsystem processes the relevant events, stores the corresponding notification and propagates it to connected clients through a real-time communication channel.
The workflow is the following:
- A domain event is generated by a service.
- The notification subsystem consumes the event.
- A notification entity is created and stored.
- The notification is delivered to relevant connected clients in real-time.
This mechanism allows the system to react promptly to user-relevant events while maintaining a decoupled architecture.
4.4 - Architecture
4.4.1 - Architectural Style
The system is designed according to a microservices architecture. The application is decomposed into a set of small, independently deployable services, each responsible for a specific bounded context: user, event, interaction, chat, ticketing and notification.
Each microservice encapsulates its own domain logic and adopts the database-per-service pattern.
When shared information is required (e.g., basic user data such as id, name and avatar needed by the chat or interaction services), it is propagated via domain events rather than retrieved through synchronous queries. This intentional data duplication reduces communication overhead and keeps services decoupled.
Moreover, this design avoids the bottleneck that would arise from sharing a single database across multiple services and guarantees strong data ownership by preventing services from directly accessing another service's data store.
Inter-service communication
Two complementary communication styles are adopted:
Synchronous (HTTP REST): used when fulfilling a request requires invoking an operation or retrieving data from another service, or to propagate state changes immediately to dependent services. For example, when an event is created, the
eventservice notifiesticketingvia its internal API so that ticket-related operations can proceed right away.Asynchronous: used to propagate state changes across service boundaries without creating runtime dependencies between them and to push real-time updates to connected clients. Three mechanisms are in place:
- Domain events (RabbitMQ): services publish events to the message broker; subscribers consume them independently. For example, when an event is published, the
eventservice emits anEventPublisheddomain event consumed by thenotification,ticketingandinteractionservices. - WebSocket (Socket.IO): used by the
notificationservice to maintain persistent connections with clients, enabling server-side push of real-time updates without polling. For example, whennotificationreceives anEventPublisheddomain event, it delivers an update to the relevant connected clients. In this case, users following the organization that published the event. - Webhooks: used for third-party integrations that push notifications into the system, for example payment provider (Stripe) callbacks delivered to the
ticketingservice. The receiving service processes the incoming HTTP call asynchronously without blocking any client-facing request.
- Domain events (RabbitMQ): services publish events to the message broker; subscribers consume them independently. For example, when an event is published, the
API gateway
All external traffic flows through an API gateway implemented with Traefik, which acts as a single entry point and keeps the internal service topology invisible to clients.
Motivation for the architectural choice
Service independence: each service can be developed, tested and deployed independently.
Scalability: services can scale horizontally according to their specific load.
Loose coupling: the combination of database-per-service and event-driven communication minimises direct dependencies, improving maintainability.
Data isolation: each service's database schema evolves independently, preventing unintended cross-service coupling.
Resilience and fault isolation: failures are contained within individual services; asynchronous communication through the message broker allows a service to be temporarily unavailable without blocking the rest of the system.
4.4.2 - Infrastructure
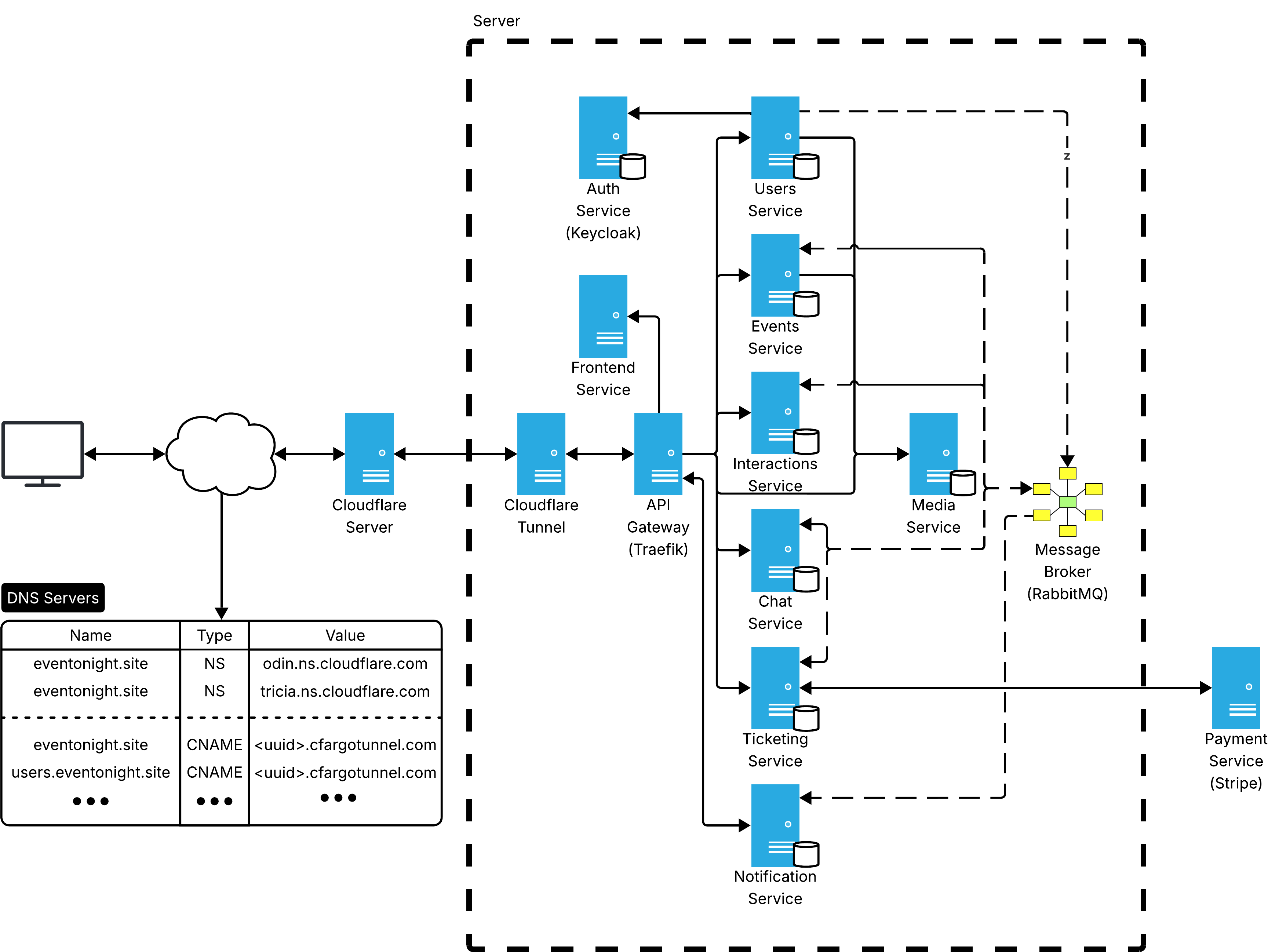
Components
All infrastructural components are listed in the table below.
| Component | Technology | Description |
|---|---|---|
| DNS / TLS | Cloudflare | Authoritative DNS and TLS termination |
| Tunnel daemon | cloudflared | Maintains an outbound encrypted tunnel to Cloudflare; no inbound ports required on the cluster |
| API gateway / Reverse proxy | Traefik v3 | Single entry point for all external HTTP/WebSocket traffic; handles routing, load balancing, rate limiting, retries, circuit breaking and request timeouts; discovers services via Docker label-based configuration |
| Backend services | Scala 3 + Cask | user, event |
| Backend services | NestJS (Node.js) | chat, interaction, ticketing |
| Backend services | Express (Node.js) | media, notification |
| Frontend | Vue 3 + Vite | Single-page application served as static assets |
| Identity provider | Keycloak | user authentication and JWT issuance |
| Message broker | RabbitMQ | Asynchronous event delivery via a topic exchange |
| Document databases | MongoDB | One dedicated instance per service |
| Relational database | PostgreSQL | Backing store for Keycloak |
| Object storage | MinIO | Binary file and image storage for the media service |
| Payment provider | Stripe (external) | Third-party payment processing |
| Seed service | Node.js | Populates databases with initial data on first deployment |
Network distribution
With the exception of Stripe, all components run inside a single host using Docker Compose. No service port is exposed to the public internet, the only inbound path is through the Cloudflare tunnel.
Two categories of Docker bridge networks are used:
eventonight-network: shared by all application services, Traefik, RabbitMQ and Keycloak. Used for inter-service communication and Traefik routing.<service>-network: one private network per service, shared exclusively between the service, its database instance and any auxiliary containers (e.g. provisioning scripts that perform initial setup, as in the case of Keycloak). This enforces database isolation, no other service can reach another service's database.
Service discovery
External clients resolve subdomains through Cloudflare's authoritative DNS. Each subdomain is a CNAME record pointing to <uuid>.cfargotunnel.com, which resolves to a Cloudflare edge IP. Traffic enters the cluster through the cloudflared tunnel and is handed off to Traefik.
Inside the host, discovery is handled by Docker Compose:
- Internal DNS: Compose registers each service by name in the internal DNS (e.g.,
http://users:9000,amqp://rabbitmq:5672). No manual registration is required. - Traefik routing: Traefik watches the Docker API for label changes and rebuilds its routing table automatically when services are started or stopped.
4.4.3 - Data Flow
Synchronous request flow (HTTP REST)
Browser → Cloudflare (DNS + TLS) → cloudflared → Traefik → Service → Database → responseThe browser sends an HTTPS request to a subdomain (e.g., events.eventonight.site). Cloudflare resolves the DNS and terminates TLS, then injects the request into the persistent encrypted tunnel (QUIC) maintained by cloudflared on the cluster. Traefik receives it, matches the Host header against its routing rules and forwards the request to the target service. The service handles the request, queries its own database instance and returns the response through the same chain.
Asynchronous event flow (AMQP)
Service → Exchange (eventonight) → Queue (per-service) → Consumer service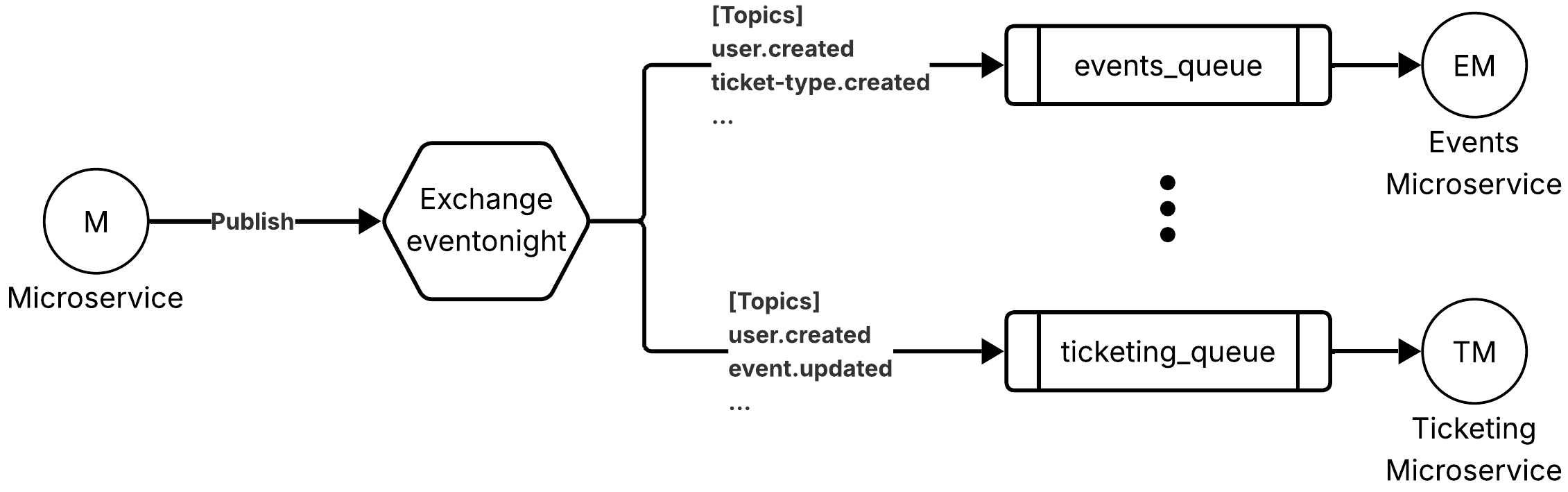
RabbitMQ uses a single topic exchange named eventonight. Each consuming service has a dedicated queue bound to the exchange with a set of topic subscriptions (e.g., ticketing_queue binds to user.created, event.updated and many others). When a service publishes a domain event with a routing key, the exchange fans it out to every queue whose binding pattern matches, without the publisher knowing who the consumers are.
Real-time push (WebSocket)
notification service → Socket.IO → BrowserThe notification service consumes events from its queue and pushes real-time updates to the relevant connected clients over WebSocket (Socket.IO).
Webhook flow (Stripe → ticketing)
Stripe → Cloudflare → cloudflared → Traefik → ticketing (acknowledged immediately, processed asynchronously)Stripe delivers payment event callbacks via HTTP POST to the ticketing service. The service responds immediately with 200 OK and processes the event asynchronously, without blocking any client-facing operation.
4.4.4 - Web API
All application services expose a REST API, accessible externally via Traefik at <service>.eventonight.site. Every protected endpoint requires a JWT Bearer token in the Authorization header, issued by Keycloak and validated independently by each service using Keycloak's public key, no centralised auth gateway is needed.
The notification service additionally exposes a WebSocket endpoint.
4.4.5 - Scalability and High Availability
The current deployment runs all components on a single host using Docker Compose. Each service runs as a single container instance, which provides basic availability but represents a single point of failure at the host level.
The architecture below is designed to transition to high availability by adopting Docker Swarm.
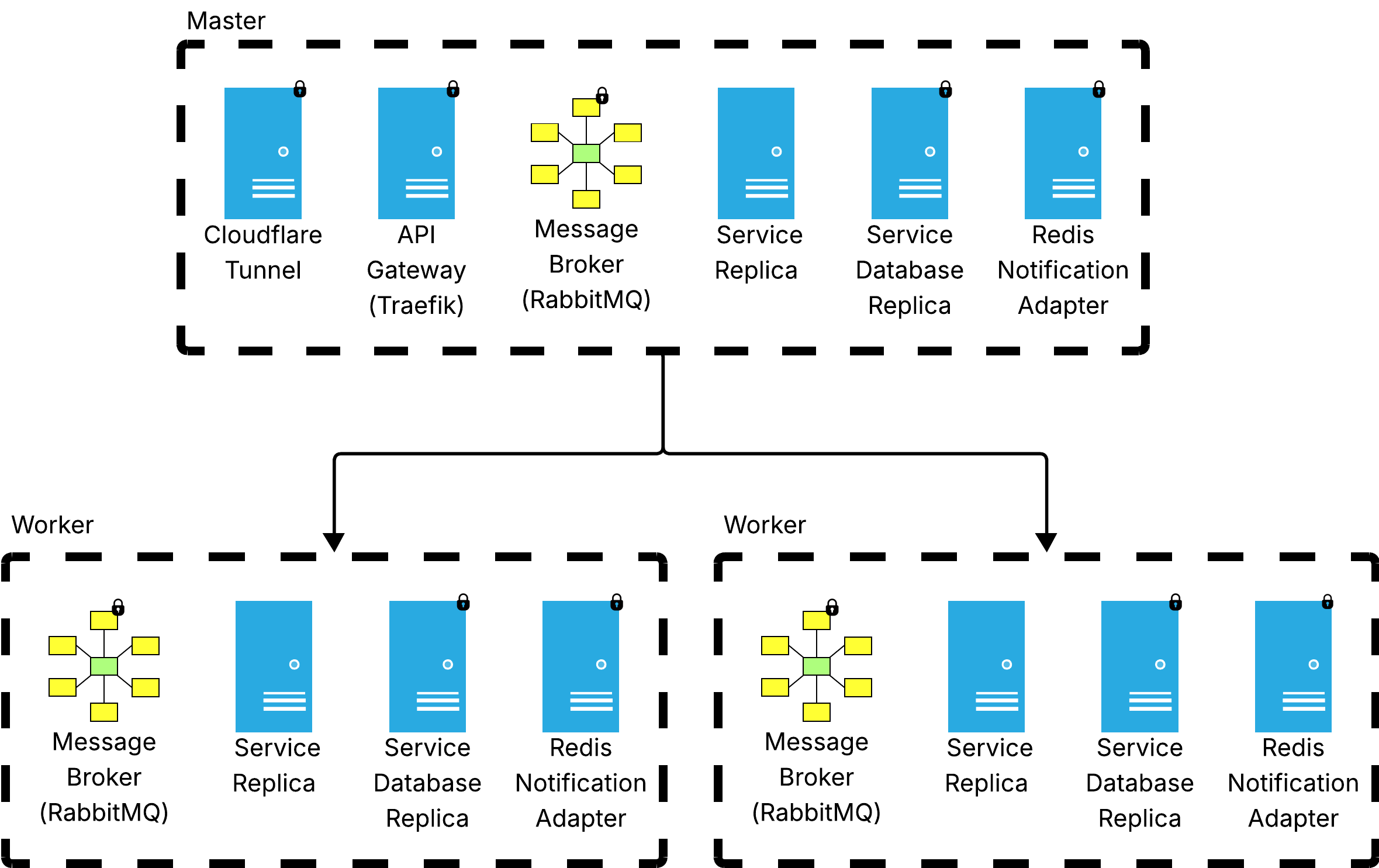
Even on a single node, Swarm already provides a first step toward HA through rolling updates, services can be updated replica by replica with zero downtime, unlike a plain Compose deployment where an update implies a brief interruption. Moving to a multi-node cluster then enables true HA by distributing replicas across machines, so that the failure of a node does not take down the service.
However, adding nodes and replicas is a necessary but not sufficient condition for HA, it also requires deliberate design choices at the infrastructure level and at the application level to preserve correctness: stateful services require dedicated replication strategies and deploying multiple replicas of a service introduces competing consumer scenarios on the broker that must be explicitly handled.
Cluster topology
For true HA, the Swarm should have at least three manager nodes. Swarm managers use the Raft consensus protocol to maintain cluster state and an odd number of managers is required to form a quorum and tolerate node failures (three managers tolerate one failure). Each manager node should run its own Traefik and cloudflared instance, so Cloudflare load-balances incoming traffic across all managers automatically.
Service placement
Stateless application services can be freely distributed across nodes. Stateful services (RabbitMQ and databases) require placement constraints to be distributed and binded on different machines. Manager nodes should be set to drain availability so the Swarm scheduler assigns no application workloads to them, keeping them dedicated exclusively to cluster management and incoming traffic.
Message broker with multiple consumers
Scaling application services to multiple replicas introduces a non-trivial consideration for broker consumption. The current setup uses a single active consumer per queue: only one replica consumes from a given queue at a time, guaranteeing FIFO message processing. This is sufficient for HA because if the active consumer fails, another replica takes over, but it does not improve throughput.
To scale throughput beyond a single consumer, more refined strategies can be explored:
- Consistent hash exchange: a RabbitMQ plugin that replaces the standard topic exchange with a hashing layer. Using that, messages are routed to one of N queues based on a hash of the routing key, allowing N consumers to process in parallel while preserving per-key ordering.
- Streams / Super Streams: RabbitMQ Streams provide a persistent, replayable log. Super Streams partition a logical stream across multiple physical streams, each consumed by a dedicated replica, combining throughput scaling with ordering guarantees per partition.
- Sequence fields: adding a monotonically increasing
versionorseqfield per entity allows consumers to detect and discard out-of-order messages regardless of the consumption strategy adopted.
What changes with Swarm:
cloudflaredand Traefik scale with the number of manager nodes, one instance per manager. Traefik natively supports Swarm mode via the Docker API.- Stateless application services can be scaled to multiple replicas and distributed freely across nodes.
- Stateful services require dedicated HA strategies: MongoDB moves to a replica set (primary + secondaries) and RabbitMQ to a quorum queue cluster, both require an odd number of members (e.g. 3, 5) to guarantee quorum and avoid split-brain, ensuring data redundancy and automatic failover. Each stateful instance must be pinned to a distinct node (at most one replica per node) so that a single node failure does not take down multiple members of the same cluster. Replicated data stores also improve fault tolerance, the system continues to operate and preserves data integrity even if individual nodes are lost.
- WebSocket sticky sessions: when
notificationruns as multiple replicas, Traefik must be configured with a sticky cookie to ensure Socket.IO handshake and subsequent frames are consistently routed to the same replica. However, sticky sessions alone are not sufficient: to broadcast events to all connected clients regardless of which replica they are connected to, a Redis adapter for Socket.IO is required to propagate messages across all instances.
4.5 - Corner cases
The system is designed to be highly available and eventual consistent. Each service operates independently and failures are isolated: when a component goes down, only the functionality directly depending on it is affected, while the rest of the system continues to operate.
Fault detection
Each service exposes a /health endpoint and declares a healthcheck in Docker Compose. This allow Docker to automatically restarts or reschedules tasks that become unhealthy, making fault detection active. To further improve observability, a dedicated monitoring service could be introduced.
Startup ordering and reconnection
In a Compose deployment, dependent services use depends_on with condition: service_healthy to enforce startup ordering. In a Swarm deployment this mechanism is not available: each service must instead be resilient to the temporary unavailability of its dependencies and implement reconnection logic autonomously. Note that reconnection logic is necessary regardless of the deployment model, as dependencies may also fail and recover during normal operation. All reconnection attempts, to MongoDB, RabbitMQ and other services, use an exponential backoff strategy.
Error signalling
Every API endpoint returns standard HTTP status codes to communicate failures to clients: 400 for validation errors, 401 for missing or invalid tokens, 403 for authorisation failures, 404 for resources not found, 409 for conflicts, 500 for unexpected server errors and so on. With a monitoring service in place, an alerting mechanism can be added to proactively notify on service failures.
Component failure and recovery
In a Compose deployment, all containers run with restart: unless-stopped, so Docker automatically restarts any crashed container. Docker itself is configured to start on host boot, meaning that even a full machine reboot brings the entire system back up without manual intervention. In a Swarm deployment, the restart policy is managed by the Swarm scheduler, which restarts failed tasks and, if a node goes down, reschedules its tasks onto healthy nodes automatically. In both cases, full recovery is achieved because services are resilient to dependency failures and re-establish connections autonomously.
Database failure. If a MongoDB instance goes down, its owning service remains partially operational: requests that do not require the database can still be served. The service reconnects automatically when the database comes back up. In a Swarm deployment with a replica set, a single node failure triggers an automatic primary election and the service reconnects to the new primary, avoiding a full outage. In both cases, multi-document operations are executed within MongoDB transactions, so a crash mid-operation leaves no inconsistent state, the transaction is simply rolled back.
Service failure. If a service crashes, Docker restarts it automatically. Since all writes are transactional, there is no risk of partial state being committed. However when a service crashes after initiating an outbound HTTP call to an external system (e.g. creating a Stripe checkout session or a Keycloak user) but before completing its local operations, an inconsistency may arise: the side effect on the external system has already occurred but the local state does not reflect it. In these cases specific strategy must be applied for each integration to handle it correctly.
RabbitMQ failure. All queues are declared as durable with persistent messages, so any message received by RabbitMQ before it goes down is safely stored to disk and delivered to consumers once it restarts. In a Swarm deployment with a quorum queue cluster, a single node failure does not cause an outage, the cluster continues operating as long as a majority of nodes are available and messages are replicated across them. RabbitMQ provides at-least-once delivery semantics; services handle this by designing message handlers to be idempotent. If RabbitMQ is unavailable at the moment a service needs to publish, messages are not lost since each service implements the outbox pattern.
Keycloak failure. If Keycloak goes down new logins and token refreshes will fail. However, services validate JWTs locally using Keycloak's public key, so requests carrying a still-valid token continue to be accepted until expiry. Once Keycloak restarts, authentication resumes normally.
Traefik or cloudflared failure. In a Compose deployment, external traffic cannot enter the system until Docker restarts the container and access resumes. In a Swarm deployment, both run one instance per manager node, so a single manager failure does not interrupt external traffic, Cloudflare simply routes through the remaining instances.
Ticketing crash during checkout session creation. If ticketing crashes after tickets have been reserved and the Stripe session has been created, but before send response to the client, the session will eventually expire and Stripe delivers a checkout.session.expired webhook allowing ticketing to release the reserved tickets. If the crash occurs before the Stripe session is created, no webhook will ever arrive and the tickets remain stuck in PENDING; a background cleanup job on timed-out pending orders would be needed to handle this case.
Ticketing unavailability. Webhook callbacks from Stripe cannot be processed. Stripe automatically retries undelivered events for up to three days, so the ticketing service will receive and process them once it recovers, without any data loss.
Dual notification path (sync + async). When an event is created, the event service notifies ticketing synchronously via HTTP call to an internal endpoint, without waiting for the asynchronous domain event to arrive. The RabbitMQ message still follows as a fault-tolerance fallback.
User crash during register and password update. If user crashes after creating the account in Keycloak but before persisting the user record locally, the user exists in the identity provider but not in the user service. On the next login attempt, Keycloak authenticates the user and issues a valid JWT, but user has no matching record. A recovery strategy can be to detect this condition at login time and create a minimal empty profile automatically, mirroring what registration would have done. For password updates, a crash mid-operation leaves the state consistent but the user may not have been correctly notified of the outcome; a "forgot password" flow provides a user-friendly self-service recovery path in this case.
Consistent backup. Because each service owns its own database, there is no single point from which to take a globally consistent snapshot. Backing up each database independently means the captured states may be at slightly different points in time. Full cross-service consistency at backup time is not achievable without a distributed snapshot protocol. One practical mitigation is to temporarily halt writes across all services, snapshot all databases simultaneously, then resume, guaranteeing consistency at the cost of a short downtime.